Most impactful AI trends of 2018: the rise of ML Engineering

2019, the year for tool builders
The field of Machine Learning (ML) has been consistently evolving since Data Science started gaining traction in 2012. However, I believe 2018 was a critical inflection point in the ML industry. After helping Insight Fellows build dozens of ML products to get roles on applied ML teams and reading through both corporate and academic published research, I’ve seen more need for engineering skills than ever before.
As a field that has consistently toed the line between its origins in academic research and the need to serve customer needs, it has often been hard to reconcile engineering standards with ML models. As both research and applied teams are doubling down on their engineering and infrastructure needs, the nascent field of ML Engineering will build upon 2018’s foundation and truly blossom in 2019.
To illustrate this, I wanted to both:
- Share back three of the key trends I observed in 2018
- Draw a parallel to how I think they’ll affect 2019 in three key ways
Three takeaways from 2018
Both in research and industry, ML is growing at a pace that is thrilling and exciting for the future, but can make it hard to get a sense for the direction of the field. Here are three trends I’ve identified from 2018 that I think will have an impact on ML in industry in 2019 and beyond.
1. Redefining representation learning
An Insight AI project presenting a novel photorealistic image generation method
One of the most impressive trends in 2018 has been various models’ growing ability to capture increasingly useful information in dense learned representations. Here are a few examples below:
- Generative Adversarial Networks (GAN) have existed since 2014 and have grown from an exciting research proposition to a cutting edge technique. The ability of these models to learn a condensed representation allows them to be applied as photo-realistic editors (linked above) and style transfer for dance. Recent research is further improving on the quality of these representations.
- Reinforcement Learning has had a few success stories in 2018 as well. OpenAI’s Dota 2 bot showed great promise, beating semi professional teams. A core part of the work involved reducing a complex game to a smaller learned representation (effectively a list of 1024 numbers, see here for more).
- Natural Language Processing (NLP) finally got its ImageNet moment in 2018. This past year has been called the year of transfer learning for NLP because of successful approaches in large scale language model pre-training, such as ULMFiT and BERT. Again, the key to these is to consume a large corpus of text such as the entirety of Wikipedia to learn a more useful representation of text.
Other than the quality of the representations they generate these exciting results have something else in common: they leverage an increasing amount of data and compute, which leads us to our second trend!
2. Scaling up
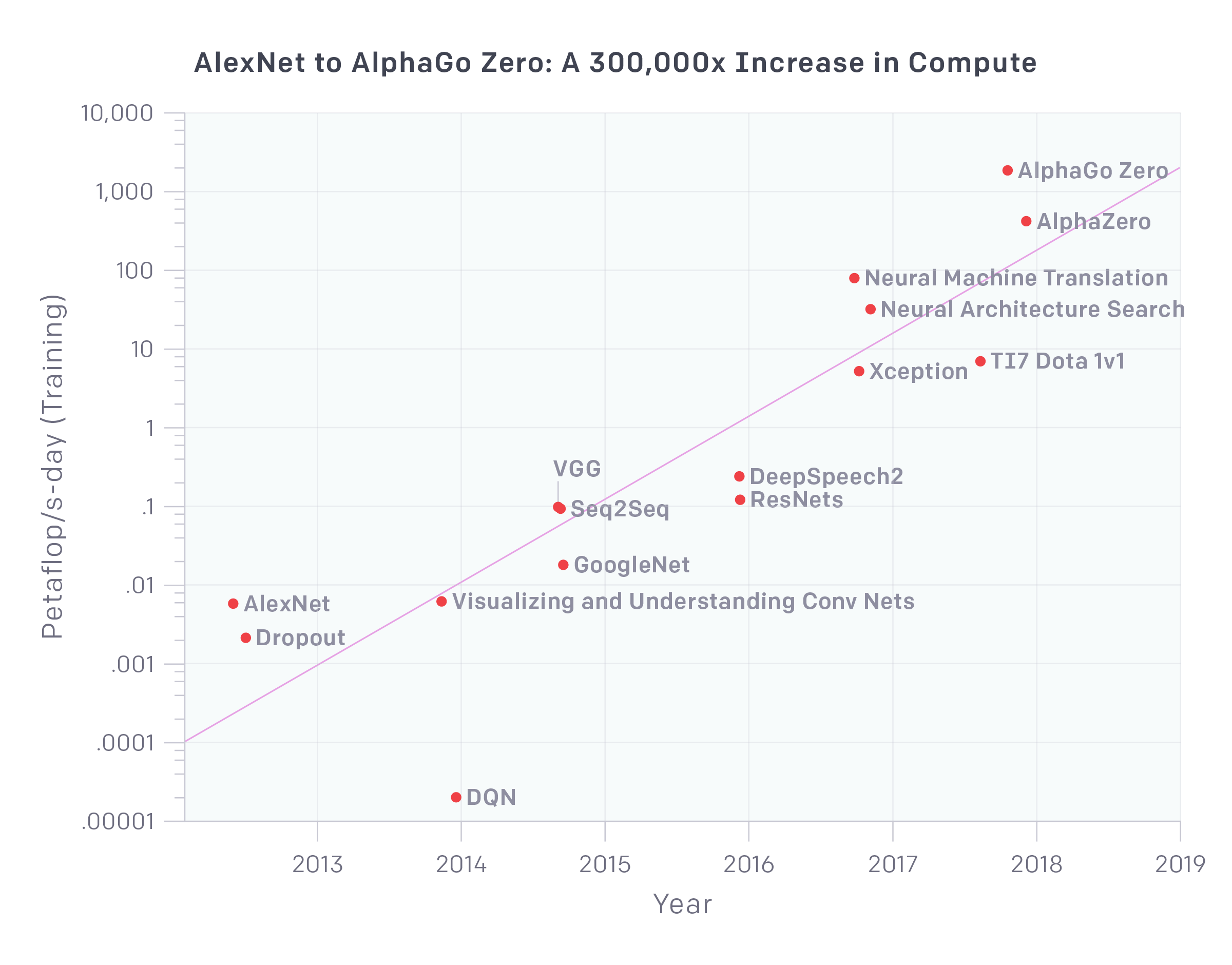
The scale of compute (credit to OpenAI)
In recent years, we have learned that when it comes to performing on well-defined tasks, such as standard datasets or game environments, larger datasets and additional compute will help us push performance further.
In fact, if we look back to the examples in the representation learning section, they all leveraged a larger dataset or more compute:
- Many GAN improvements such as BigGAN have relied on massively larger datasets, and training models for longer.
- OpenAI’s Dota 2 bot plays 180 years worth of games against itself every day during training.
- NLP models learn better representations by leveraging the entirety of Wikipedia before even starting to train on their actual task!
While the strategy of scaling up has shown promise on academic tasks, this post focuses on practical ML in industry where there is often no standard definition of a task or dataset, and the data distributions we are trying to understand are constantly shifting in nature. This requires an entirely different set of tools.
In fact, the disparity between research results we see today (see video of the dance paper above) and what has been deployed in most products except by a few leading companies points to a wide gap between researchers and well funded teams, and other practitioners and startups.
3. Building internal platforms
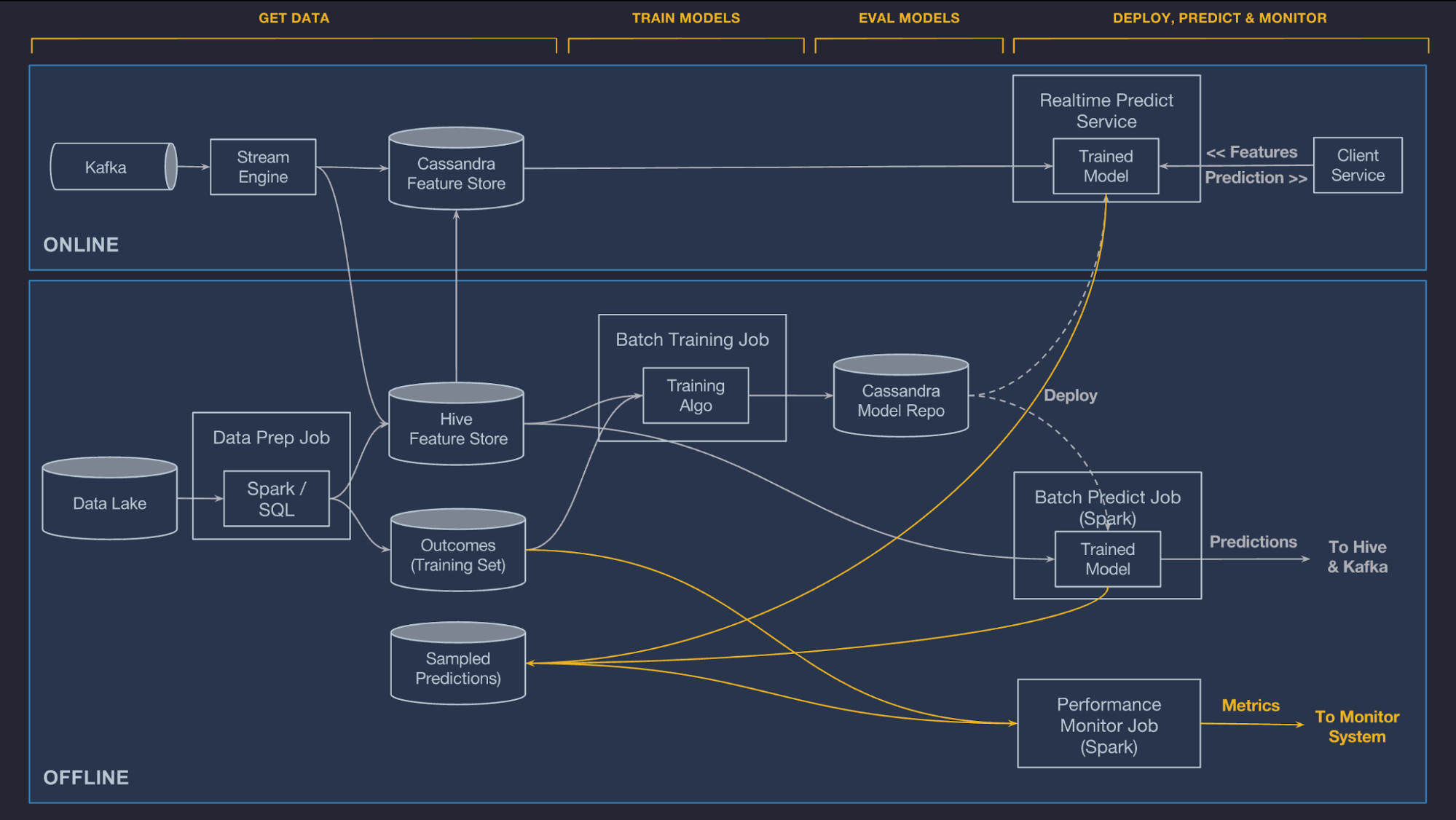
An architecture diagram of Uber’s Michelangelo
This past year, more companies have started to publicize the scale of the tooling they have built internally to help support their ML efforts. Here are a few personal favorites:
- Uber released two more articles in their series explaining Michelangelo (one, two and three) which I highly recommend reading.
- Airbnb shared a very candid and fascinating account of the trials and tribulations of applying Deep Learning to search rankings.
- Netflix explained the infrastructure they have put in place to use notebooks in production in these two posts.
Seeing how some of the best engineering teams in industry have tackled the challenge of delivering ML to their users is inspiring. At the same time, because building such platforms represents such a herculean effort, many practitioners advise smaller teams to avoid building their own ML platform.
This leaves most small to medium sized teams in a no man’s land between cobbling together offerings from service providers that do not exactly fit their needs, and taking on significant engineering costs. There is a growing gap pointing to a need for a set of frameworks like Tensorflow and Spark, and of widely shared best practices for all the parts of ML that are not purely model training.
More and more people realize that nobody needs yet another library or tutorial to build a 3-layer neural network on MNIST. Consequently, many startups have entered the space of data and model infrastructure, management and deployment, and educational resources have started to focus on these aspects more. This is why, I fundamentally believe that 2019 will be the year of ML Engineering. I’ll explain how I see this unfolding below!
Three ways ML Engineering will grow in 2019
A common warning shared with aspiring Data Scientists is that 90% of the work is about gathering and cleaning data, or validating, deploying, and monitoring models. If that is the case, why are 90% of the frameworks and Github repositories (see this list for example)focused on model building?
A part of the job that demands so much of a practitioner’s time should have proper tooling support.
Now that many large companies have laid the ground work for best practices when it comes to building ML products, and that many teams are being forced to reinvent the wheel when it comes to building the majority of their modeling pipeline, we are finally at the right moment for open-source ML Engineering frameworks.
1.Creating tooling for all Data Scientists

What will be the Keras of data exploration?
Amazing libraries such as Keras, Tensorflow, PyTorch, and fast.ai have made it easier than ever to define and train custom models. At the same time, many companies have launched hosted services that complement such libraries by helping with data visualization, cleaning, model serving, and experiment tracking.
The problem with many of these services, is that ML Engineering needs are very use case specific, and often require the flexibility of an extensible open source framework. This is quite similar to Google Cloud offering APIs to call standard computer vision models: it is valuable for a subset of users, but would never be considered a replacement for Keras. The question now is, what will be the Keras of data exploration and cleaning?
There are many parts to ML Engineering work, and we could see frameworks being extended to cover multiple aspects, or separate solutions winning out in each of these categories. Here are a few domains to watch for:
- Data exploration, labeling, and versioning.
- Model automated testing, validation, serving, and lifecycle management.
- Experiment tracking, hyperparameter optimization, and experimentation tooling in general
Startups have started to propose solutions for many of these problems, but none have really helped define standards as widely adapted as Tensorflow and Pytorch are for model building. This is part of a larger trend, the lack of best practices for ML Engineering.
2. Defining a clear path to production
What will be the agile of ML? (credit InfoQ)
More and more developers can train a model to a given level of performance. However, when building a product you usually simply have a goal, with no attached dataset. This requires being able to:
- Go from a product goal to formulating a learning problem that will both be feasible, and generate a useful model.
- Efficiently gather a dataset, build a simple model, and consistently improve both the model and the dataset (many can improve a model given a standard dataset, but few know how to iterate on a dataset, see here for more)
- Decide what it means for a model to actually be ready to be put in front of users.
- Monitor deployed models to know when and how to update them.
These are crucial skills, that usually make or break a data product, and there is a shortage of resources and best practices to help guide practitioners. When surveyed, this is the type of content that most experienced ML professionals in my network want more of, since it related to the problems they face every day, which leads me to my last point.
3. Promoting resources that best prepare aspiring professionals
When it comes to recruiting, Hiring Managers of teams all over the valley most often complain that while there is no shortage of people able to train models on a dataset, they need engineers that can build data driven products.
At the same time, most aspiring Data Scientists and ML Engineers are most excited about training models on provided datasets. This excitement is usually inspired by blogs and courses that have focused on that part of the work, instead of data gathering/labeling/cleaning and model deployment.
This leads to a frustrating disconnect between companies looking to hire and newcomers. While professional Fellowships like Insight Data Science have worked on bridging this gap since Data Science started, I am looking forward to more resources that promise to teach ML focusing on the 90% of the field that is not model building!
Looking forward: 2019 resolutions
The march towards ML Engineering has already sped up in 2018, and at Insight, we’ve been hard at work to help more people transition to the field successfully (learn more here!). In addition, throughout this year, I will focus more of my writing on the 90% of ML work that have been ignored so far, but that is so crucial to success in industry.
If you’d like to hear more advice, recommendations, and tutorials, feel free to join the mailing list below!
Emmanuel